
【编者按】本文作者为 Bill Bejeck,主要介绍如何有效利用新的 Apache Kafka 客户端来满足数据处理需求。文章系国内 ITOM 管理平台 OneAPM 编译呈现,以下为正文。
如果你使用的系统需要传输大量数据,就算你没用过 Kafka,很有可能已经听说过它了。从较高层面来说,Kafka 是一个对错误零容忍、分布式的发布订阅信息系统,设计目的是提供高速服务及处理成千上万信息的能力。Kafka 提供多种应用,其中一种是实时处理。实时处理通常包括读取主题(源)的数据进行分析或转换工作,然后将结果写入另一个主题(sink)。目前要完成这些工作,你有以下两种备选:
-
通过 KafkaConsumer 使用自定义代码来读取数据,然后通过 KafkaProducer 写出数据。
-
使用发展成熟的流处理框架,例如 Spark Steaming、Flink 或者 Storm。
虽然两种方法都很好,在某些情况下,如果能有一个处于两种之间的方法就更好了。为此,《Kafka 改进方案》流程提出了一个处理器接口。处理器接口的目的是引入一个客户端,以便处理 Kafka 消耗的数据,并将结果写入 Kafka。该处理器客户端包括两个组成部分:
-
一个“低层级”的处理器,能够提供数据处理、组合处理和本地状态存储的接口
-
一个“高层级”的流 DSL,能够满足大部分处理执行需求。
接下来将会有一系列文章介绍新的 Kafka 处理器客户端,本文主要介绍“低层级”的处理器功能。在后续文章中,将会介绍“高层级”的 DSL 和涉及到其它技术的高级用例。如想了解处理器客户端的动机和目标的完整描述,请阅读《方案》原文。免责声明:本人与 Confluent 并无任何关系,仅仅是 Kafka 的一名热心用户。
处理器接口的潜在用例
在笔者看来,处理器接口是个有用工具的原因有以下几点:
-
在处理奇异值时需要发出通知或警报。换句话说,业务需求就是:你不需要建立模型或在其它被处理的数据语境中检查这个值。举个例子,当有人使用虚假信用卡时,你希望能立即收到通知。
-
在进行分析时筛选数据。理想状态下,筛选出中到高比例的数据应该重新分区,来避免数据倾斜问题。分区操作成本很高,因此通过筛选哪些数据要发送到你的分析群集,就可以省去筛选和重新分区步骤。
-
你只想对源数据的某一部分进行分析,同时把所有数据传输到另一个存储空间。
第一个处理器范例
在第一个处理器范例中,笔者要转化虚构的客户购买数据,并进行以下操作:
-
掩藏信用卡号的处理器。
-
用于收集客户名字和消费金额的处理器,这些信息将会用于一个奖励项目。
-
用于收集邮编和购买商品的处理器,这些信息可以帮助判断消费者的购物模式。
以下是处理器对象的简要介绍。三个处理器都继承了 AbstractProcessor 类,该类提供了punctuate 和 close 方法的空操作重写。在本范例中,只需要实现 process 方法,该行为就会执行到每条信息。任务完成后,将会调用 context().forward 方法,它会将修改后的或者新的键值对转发给下游的消费者。(context() 方法会检索 init 方法在父类中预置的 context 实例变量)。然后, context().commit 方法被调用,提交包括信息偏移在内的流当前状态。
打造处理器图形
现在需要定义有向无环图(DAG)来决定信息的流向。这是关系到处理器接口是否会“出现偏差”的地方。要打造处理器节点图,需要用到拓扑构造器(ToplogyBuilder)。虽然笔者的信息属于 JSON,但还是需要定义 序列化 和 反序列化 实例,因为处理器按照类型来处理。下面是来自 PurchaseProcessorDriver 的一部分代码,它们构成了图形拓扑、序列化程序和反序列化程序。
//Serializers for types used in the processors
JsonDeserializer<Purchase> purchaseJsonDeserializer = new JsonDeserializer<>(Purchase.class);
JsonSerializer<Purchase> purchaseJsonSerializer = new JsonSerializer<>();
JsonSerializer<RewardAccumulator> rewardAccumulatorJsonSerializer = new JsonSerializer<>();
JsonSerializer<PurchasePattern> purchasePatternJsonSerializer = new JsonSerializer<>();
StringDeserializer stringDeserializer = new StringDeserializer();
StringSerializer stringSerializer = new StringSerializer();
TopologyBuilder topologyBuilder = new TopologyBuilder();
topologyBuilder.addSource("SOURCE", stringDeserializer, purchaseJsonDeserializer, "src-topic")
.addProcessor("PROCESS", CreditCardAnonymizer::new, "SOURCE")
.addProcessor("PROCESS2", PurchasePatterns::new, "PROCESS")
.addProcessor("PROCESS3", CustomerRewards::new, "PROCESS")
.addSink("SINK", "patterns", stringSerializer, purchasePatternJsonSerializer, "PROCESS2")
.addSink("SINK2", "rewards",stringSerializer, rewardAccumulatorJsonSerializer, "PROCESS3")
.addSink("SINK3", "purchases", stringSerializer, purchaseJsonSerializer, "PROCESS");
//Use the topologyBuilder and streamingConfig to start the kafka streams process
KafkaStreams streaming = new KafkaStreams(topologyBuilder, streamingConfig);
streaming.start();
There’s several steps here, so let’s do a quick walkthrough
上面的代码涉及到几个步骤,以下是其简介:
-
在第11行有个源节点叫做“SOURCE”,一个用于键的 StringDeserializer 以及生成的 JsonSerializer 来处理 Purchase 对象,和供给源代码的1到N个主题。本范例中使用的是1个主题“src-topic”的输入信息。
-
接下来开始添加处理器节点。addProcessor 方法以一个 Strings 命名,一个 ProcessorSupplier,以及1到N个父节点。在本范例中,第一个处理器是“SOURCE”节点的孩子,同时又是后两个处理器的父亲。在这里需要注意 ProcessorSupplier 的句法。该代码在利用方法处理(method handles),后者可以在 Java8中用作供应实例的 lambda 表达式。代码继续用同样的方式定义接下来的两个处理器。
-
最后添加 sink(输出主题)来完成信息通道。addSink 方法用到一个 String 名字、主题名字、键值序列化程序、值序列化程序和1到 N 个父节点。在3个 addSink 方法中,可以看到之前在代码中创建的 JSONDeserializer 对象。
下面是拓扑构造器(TopologyBuilder)的最终结果图示:
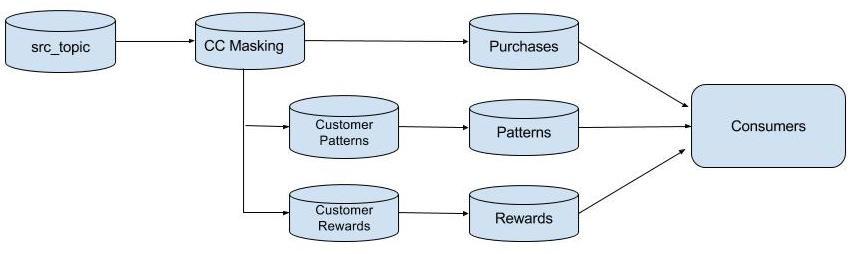
状态处理器
处理器接口并不仅限于处理当前收到的值,还能维护集合、总和过程中使用的状态,或者连接将要收到的信息。为了充分利用状态处理功能,在创建处理拓扑时,使用 TopologyBuilder.addStateStore 方法创建一个 KeyValueStore。可以创建两种存储区:(1)内存式的;(2)利用堆外存储的 RocksDB 存储。选择哪个取决于值的有效时长。对于数量较多的动态值,RocksDB 比较适合,对于时效较短的词条,内存式更适合。在指定 String、Integer 或较长的键值和值时,Stores 类别提供序列化、反序列化实例。但是如果使用自定义类型的键值或值时,需要提供自定义的序列化程序和反序列化程序。
状态处理器范例
在本范例中,将会看到 process 方法和另外两个重写方法:init 和 punctuate。process 方法抽取股票代号,更新或创建交易信息,然后把汇总结果放入存储区。
在 init 方法中的操作有:
设置 ProcessorContext 引用。
用 ProcessorContext.schedule 方法,以便控制 punctuate 方法的执行频率。在本范例中频率为10秒1次。
给构建 TopologyBuilder(下文将会谈到)时创建的状态存储区设置一个引用。
punctuate 方法会迭代存储区内的所有值,并且一旦它们在过去11秒内更新,StockTransactionSummary 对象就会被发送给消费者。
利用状态存储区打造一个拓扑构造器
跟前面的例子一样,看处理器代码只完成了一半的工作。以下是部分源代码,创建了 TopologyBuilder,其中包括一个 KeyValueStore:
TopologyBuilder builder = new TopologyBuilder();
JsonSerializer<StockTransactionSummary> stockTxnSummarySerializer = new JsonSerializer<>();
JsonDeserializer<StockTransactionSummary> stockTxnSummaryDeserializer = new JsonDeserializer<>(StockTransactionSummary.class);
JsonDeserializer<StockTransaction> stockTxnDeserializer = new JsonDeserializer<>(StockTransaction.class);
JsonSerializer<StockTransaction> stockTxnJsonSerializer = new JsonSerializer<>();
StringSerializer stringSerializer = new StringSerializer();
StringDeserializer stringDeserializer = new StringDeserializer();
builder.addSource("stocks-source", stringDeserializer, stockTxnDeserializer, "stocks")
.addProcessor("summary", StockSummary::new, "stocks-source")
.addStateStore(Stores.create("stock-transactions").withStringKeys()
.withValues(stockTxnSummarySerializer,stockTxnSummaryDeserializer).inMemory().maxEntries(100).build(),"summary")
.addSink("sink", "stocks-out", stringSerializer,stockTxnJsonSerializer,"stocks-source")
.addSink("sink-2", "transaction-summary", stringSerializer, stockTxnSummarySerializer, "summary");
System.out.println("Starting KafkaStreaming");
KafkaStreams streaming = new KafkaStreams(builder, streamingConfig);
streaming.start();
System.out.println("Now started");
这段代码在创建序列化、非序列化和拓扑构造器方面并无不同。但是有一点不同。第13、14行创建了一个内存存储区(命名为“summary”),供处理器使用。传到 Stores.create 方法的名字跟前面在处理器 init 方法中用来重写存储区的名字一样。在指定键值时,可以使用便捷的 Stores.withStringKeys() 方法,因为 Strings 本来就是它支持的类型,不需要提供参数。但是因为使用了类型化的值,所以使用了 withValues 方法,并提供了序列化和非序列化实例。
用范例代码运行处理器
本文所示范例可与实时 Kafka 群集进行对比。指导说明参见本文的 github 资源库。
结论
目前为止,笔者已经介绍了 Kafka 处理器接口的“低层级”部分。希望能让大家领略到这个新接口能够给 Kafka 的新老用户带来的实用性和多样性。在下一篇文章中,笔者将会介绍“高层级”的 DSL 接口,以及连接、时窗功能等问题。最后要强调的一点,就是处理器接口和 Kafka 流还在继续开发中,很快将会有更新。
本文系 OneAPM 工程师整理呈现。OneAPM 能为您提供端到端的应用性能解决方案,我们支持所有常见的框架及应用服务器,助您快速发现系统瓶颈,定位异常根本原因。分钟级部署,即刻体验,性能监控从来没有如此简单。想阅读更多技术文章,请访问 OneAPM 官方技术博客。
原文地址:https://dzone.com/articles/introducing-the-kafka-processor-client
未经允许不得转载