
##简介:
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Kafka如下特性,受到诸多公司的青睐。
1、高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息(核心目标之一)。
2、支持通过Kafka服务器和消费机集群来分区消息
…………
##场景:
Kafka的作用我就不在这BB了,大家可以瞅瞅http://blog.jobbole.com/75328/,总结的非常好。
Kafka监控的几个指标
1、lag:多少消息没有消费
2、logsize:Kafka存的消息总数
3、offset:已经消费的消息
lag = logsize - offset, 主要监控lag是否正常
##脚本:
- spoorer.py文件,获取Kafka中的监控指标内容,并将监控结果写到spooer.log文件中
crontab设置每分钟执行spoorer.py
# -*- coding:utf-8 -*-
import os, sys, time, json, yaml
from kazoo.client import KazooClient
from kazoo.exceptions import NoNodeError
from kafka import (KafkaClient, KafkaConsumer)
class spoorerClient(object):
def __init__(self, zookeeper_hosts, kafka_hosts, zookeeper_url='/', timeout=3, log_dir='/tmp/spoorer'):
self.zookeeper_hosts = zookeeper_hosts
self.kafka_hosts = kafka_hosts
self.timeout = timeout
self.log_dir = log_dir
self.log_file = log_dir + '/' + 'spoorer.log'
self.kafka_logsize = {}
self.result = []
self.log_day_file = log_dir + '/' + 'spoorer_day.log.' + str(time.strftime("%Y-%m-%d", time.localtime()))
self.log_keep_day = 1
try:
f = file(os.path.dirname(os.path.abspath(__file__)) + '/' + 'spoorer.yaml')
self.white_topic_group = yaml.load(f)
except IOError as e:
print 'Error, spoorer.yaml is not found'
sys.exit(1)
else:
f.close()
if self.white_topic_group is None:
self.white_topic_group = {}
if not os.path.exists(self.log_dir): os.mkdir(self.log_dir)
for logfile in [x for x in os.listdir(self.log_dir) if x.split('.')[-1] != 'log' and x.split('.')[-1] != 'swp']:
if int(time.mktime(time.strptime(logfile.split('.')[-1], '%Y-%m-%d'))) < int(time.time()) - self.log_keep_day * 86400:
os.remove(self.log_dir + '/' + logfile)
if zookeeper_url == '/':
self.zookeeper_url = zookeeper_url
else:
self.zookeeper_url = zookeeper_url + '/'
def spoorer(self):
try:
kafka_client = KafkaClient(self.kafka_hosts, timeout=self.timeout)
except Exception as e:
print "Error, cannot connect kafka broker."
sys.exit(1)
else:
kafka_topics = kafka_client.topics
finally:
kafka_client.close()
try:
zookeeper_client = KazooClient(hosts=self.zookeeper_hosts, read_only=True, timeout=self.timeout)
zookeeper_client.start()
except Exception as e:
print "Error, cannot connect zookeeper server."
sys.exit(1)
try:
groups = map(str,zookeeper_client.get_children(self.zookeeper_url + 'consumers'))
except NoNodeError as e:
print "Error, invalid zookeeper url."
zookeeper_client.stop()
sys.exit(2)
else:
for group in groups:
if 'offsets' not in zookeeper_client.get_children(self.zookeeper_url + 'consumers/%s' % group): continue
topic_path = 'consumers/%s/offsets' % (group)
topics = map(str,zookeeper_client.get_children(self.zookeeper_url + topic_path))
if len(topics) == 0: continue
for topic in topics:
if topic not in self.white_topic_group.keys():
continue
elif group not in self.white_topic_group[topic].replace(' ','').split(','):
continue
partition_path = 'consumers/%s/offsets/%s' % (group,topic)
partitions = map(int,zookeeper_client.get_children(self.zookeeper_url + partition_path))
for partition in partitions:
base_path = 'consumers/%s/%s/%s/%s' % (group, '%s', topic, partition)
owner_path, offset_path = base_path % 'owners', base_path % 'offsets'
offset = zookeeper_client.get(self.zookeeper_url + offset_path)[0]
try:
owner = zookeeper_client.get(self.zookeeper_url + owner_path)[0]
except NoNodeError as e:
owner = 'null'
metric = {'datetime':time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()), 'topic':topic, 'group':group, 'partition':int(partition), 'logsize':None, 'offset':int(offset), 'lag':None, 'owner':owner}
self.result.append(metric)
finally:
zookeeper_client.stop()
try:
kafka_consumer = KafkaConsumer(bootstrap_servers=self.kafka_hosts)
except Exception as e:
print "Error, cannot connect kafka broker."
sys.exit(1)
else:
for kafka_topic in kafka_topics:
self.kafka_logsize[kafka_topic] = {}
partitions = kafka_client.get_partition_ids_for_topic(kafka_topic)
for partition in partitions:
offset = kafka_consumer.get_partition_offsets(kafka_topic, partition, -1, 1)[0]
self.kafka_logsize[kafka_topic][partition] = offset
with open(self.log_file,'w') as f1, open(self.log_day_file,'a') as f2:
for metric in self.result:
logsize = self.kafka_logsize[metric['topic']][metric['partition']]
metric['logsize'] = int(logsize)
metric['lag'] = int(logsize) - int(metric['offset'])
f1.write(json.dumps(metric,sort_keys=True) + '\n')
f1.flush()
f2.write(json.dumps(metric,sort_keys=True) + '\n')
f2.flush()
finally:
kafka_consumer.close()
return ''
if __name__ == '__main__':
check = spoorerClient(zookeeper_hosts=‘zookeeperIP地址:端口', zookeeper_url=‘znode节点', kafka_hosts=‘kafkaIP:PORT', log_dir='/tmp/log/spoorer', timeout=3)
print check.spoorer()
- spoorer.py读取同一目录的spoorer.yaml配置文件
格式:
kafka_topic_name:
group_name1,
group_name2,
(group名字缩进4个空格,严格按照yaml格式)
- spoorer.log数据格式
{“datetime”: “2016-03-18 11:36:02”, “group”: “group_name1”, “lag”: 73, “logsize”: 28419259, “offset”: 28419186, “owner”: “消费partition线程”, “partition”: 3, “topic”: “kafka_topic_name”}
monitor_kafka.sh脚本检索spoorer.log文件,并配合zabbix监控
#!/bin/bash
topic=$1
group=$2
#$3可取值lag、logsize、offset
class=$3
case $3 in
lag)
echo "`cat /tmp/log/spoorer/spoorer.log | grep -w \\"${topic}\\" | grep -w \\"${group}\\" |awk -F'[ ,]' '{sum+=$9}'END'{print sum}'`"
;;
logsize)
echo "`cat /tmp/log/spoorer/spoorer.log | grep -w \\"${topic}\\" | grep -w \\"${group}\\" |awk -F'[ ,]' '{sum+=$12}'END'{print sum}'`"
;;
offset)
echo "`cat /tmp/log/spoorer/spoorer.log | grep -w \\"${topic}\\" | grep -w \\"${group}\\" |awk -F'[ ,]' '{sum+=$15}'END'{print sum}'`"
;;
*)
echo "Error input:"
;;
esac
exit 0
zabbix_agentd.conf扩展配置
UserParameter=kafka.lag[*],/usr/local/zabbix-2.4.5/script/monitor_kafka.sh $1 $2 lag
UserParameter=kafka.offset[*],/usr/local/zabbix-2.4.5/script/monitor_kafka.sh $1 $2 offset
UserParameter=kafka.logsize[*],/usr/local/zabbix-2.4.5/script/monitor_kafka.sh $1 $2 logsize
zabbix设置Key
kafka.lag[kafka_topic_name,group_name1]
kafka.logsize[kafka_topic_name,group_name1]
kafka.offset[kafka_topic_name,group_name1]
zabbix监控效果:
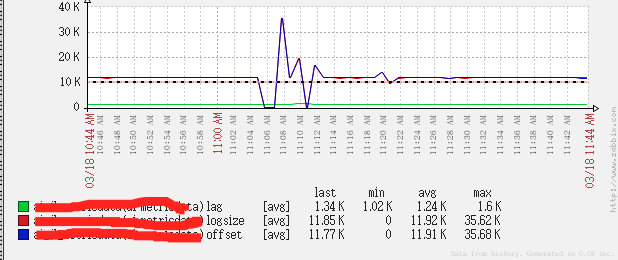
- 出现问题第一时间发送报警消息。
报警的Trigger触发规则也是对lag的值做报警,具体阀值设置为多少,还是看大家各自业务需求了。
接收告警消息可以选择邮件和短信、网上教程也比较多,教程帖子:
http://www.iyunv.com/thread-22904-1-1.html http://www.iyunv.com/thread-40998-1-1.html
如果觉得自己搞这些比较麻烦的话,也可以试试 OneAlert 一键集成zabbix,短信、电话、微信、APP啥都能搞定,还免费,用着不错。
http://www.onealert.com/activity/zabbix.html