
Docker 是构建和部署软件的一个新兴的轻量级的平台,也是一个减轻替代虚拟机的容器。Docker 通过给开发者提供兼容不同环境的镜像,成为解决现代基础设施的持续交付的一个流行的解决方案。
和虚拟机一样,容器也需要一个新的监测方法。现在有许多开源的监控软件,但部署麻烦,需要许多人力来进行后期维护,Luckily,如果你是一个 OneAPM 用户,现在你可以利用我们最新的应用产品:Cloud Insight。
如果你已经安装了 Cloud Insight 探针实现了服务器监控,接下来只需要配置一个简单的 YAML 文件,就可以实现监控不同 containers 的性能指标。
####Docker 性能监控是怎么实现的
Docker 性能监控的最简单的方法是在直接主机上运行 Cloud Insight,它可以访问容器,尤其是如果您在现有的全面的主机操作系统上部署 Docker,沿用现有的应用程序(如数据库)等。
探针在 Docker 环境中的位置如下:

由于 Docker 使用现有的内核结构(namespace 和 cgroup )来运行容器,Cloud Insight 使用本地 cgroup 的统计指标来收集 CPU,内存,运行/停止的 containers 的数量。
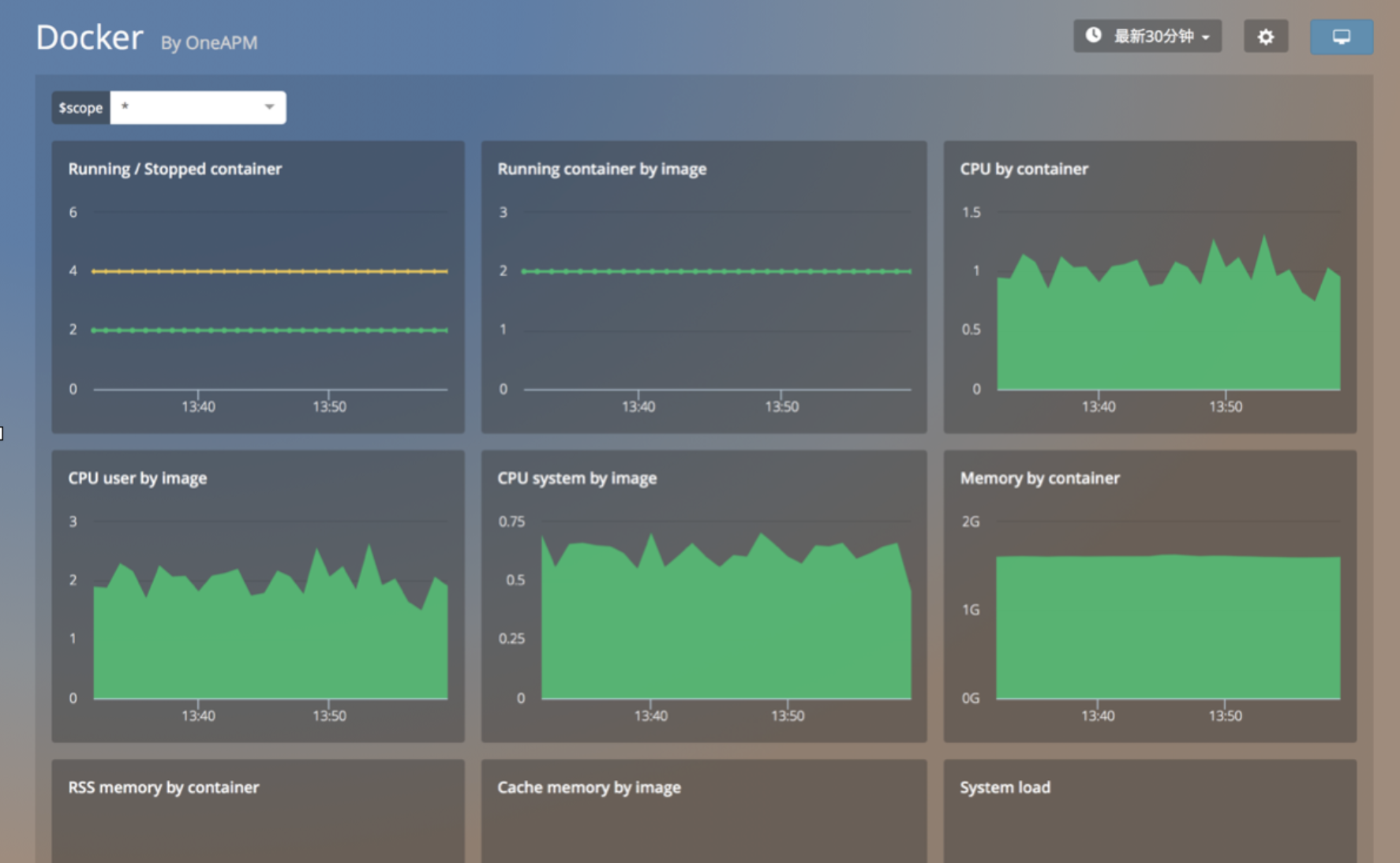
虽然这是监测 Docker 最简单的方法,但之后我们还会提供在 Docker 容器中监控所有运行的软件的探针版本,敬请期待。
####监控 Docker
用标签有效地监视多个 containers
鉴于 Docker 是易于使用的轻量级容器,你可能会在你的基础组件上处理于底层物理机或虚拟主机几倍数量的运行容器。那你是怎么花费少量时间跟踪和监视他们的呢?用 Cloud Insight 的标签(tag)。
tags 是不需要额外工作就可以监控大量容器的的关键。默认情况下,Docker 会监控你的容器并把 「name」「image」 「command」 等属性作为一个 「tag」。

####仪表盘通过标签订制指标
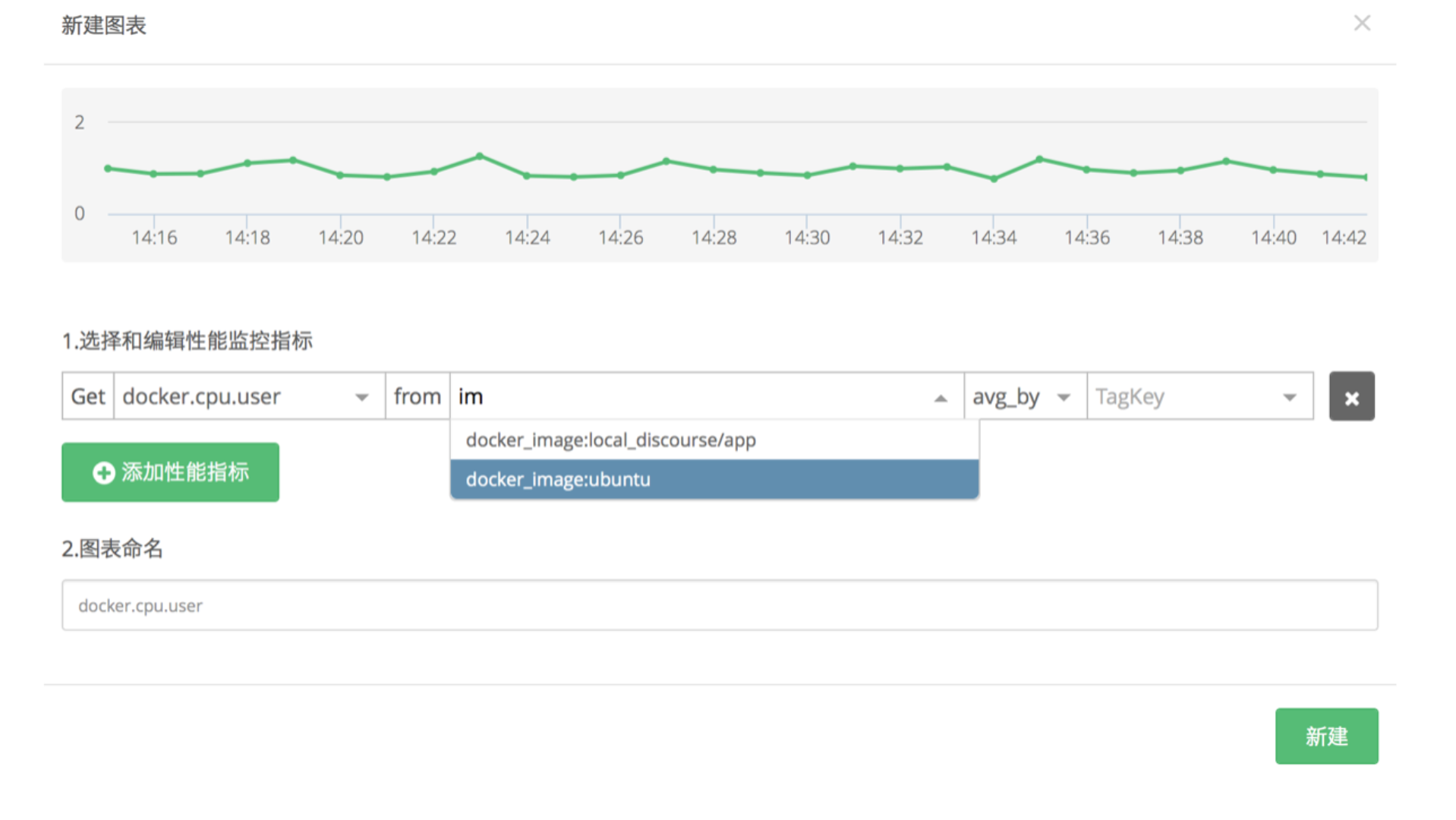
在 Cloud Insight 中,您可以在自定义仪表盘中基于一个或多个标签来显示指标。这样您就可以监控多个 containers 的特定的指标。使用 tags,你可以轻松地创建仪表盘来展示从所有容器中抽取的一个指标的图表数据。
在下面的例子中,我们通过图像分解展示出的消耗 CPU 的量。
####报警(Alert)
tags 在定义跨越集群容器的警报是非常有用的。例如,你正在运行 Redis 的容器集群,你希望在一个容器内存耗尽的时候触发报警,而不是定义每个容器一个警报,设置多个维度的报警,是我们 Cloud Insight 在做的。
你可以看看 Docker 的 运行指标指南,里面有所有指标的详细说明。
如果您想轻松地查看 Docker 的性能状况,尝试使用 Cloud Insight bate 版,安装 Cloud Insight 后简单配置即可实现。